Investigating Pre-Training Objectives for Generalization in Vision-Based Reinforcement Learning ICML 2024
{kind=link}
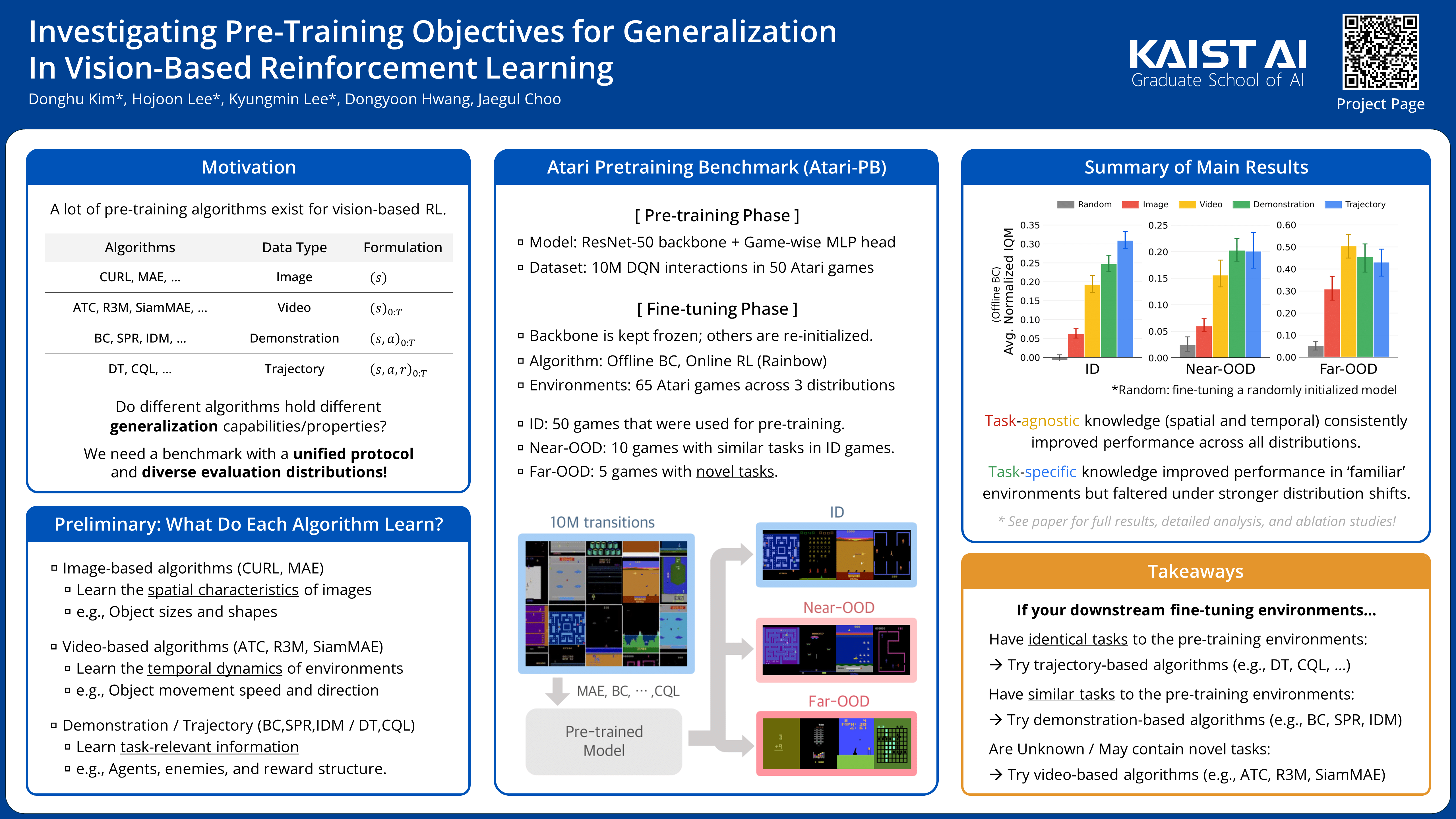
Takeaways
- Learning task-agnostic features consistently improve generalization across various distribution shifts. (e.g., identifying objects from images, understanding temporal dynamics from videos)
- Learning task-specific features improve performance in similar tasks but lose effectiveness as task distribution shifts increase. (e.g., focusing on agents from demonstrations and fitting the reward function from trajectories)
Abstract
Recently, various pre-training methods have been introduced in vision-based Reinforcement Learning (RL). However, their generalization ability remains unclear due to evaluations being limited to in-distribution environments and non-unified experimental setups. To address this, we introduce the Atari Pre-training Benchmark (Atari-PB), which pre-trains a ResNet-50 model on 10 million transitions from 50 Atari games and evaluates it across diverse environment distributions. Our experiments show that pre-training objectives focused on learning task-agnostic features (e.g., identifying objects and understanding temporal dynamics) enhance generalization across different environments. In contrast, objectives focused on learning task-specific knowledge (e.g., identifying agents and fitting reward functions) improve performance in environments similar to the pre-training dataset but not in varied ones. We publicize our codes, datasets, and model checkpoints at https://github.com/dojeon-ai/Atari-PB.
Atari-PB Overview
- 12 pre-training algorithms that use 4 different data types: Image, Video, Demonstration, Trajectory.
- 3 environment distributions: ID (50 games), Near-OOD (10 games), Far-OOD (5 games).
- A ResNet-50 model is pre-trained on a 10M pre-training dataset for 100 epochs, then fine-tuned/evaluated on each environment distribution.
Main Results and Observations
- O1: Learning task-agnostic information (Image, Video) significantly enhances performance across ID, Near-OOD, and Far-OOD environments.
- O2: Learning task-relevant information (Demonstration) further enhances ID and Near-OOD performance, but only marginally for Far-OOD.
- O3: Learning reward-specific information (Trajectory) yields best ID performance, while it shows limited generalization in Near-OOD and Far-OOD environments.
- O4: Effective adaptation in one fine-tuning scenario correlates to effective adaptation in the other.