![]()
![]()
![]()
Hi there, nice to meet you!
My name is Donghu Kim. Currently I am a research scientist at Holiday Robotics, where we are developing dexterous manipulation skills with RL in simulation.
I received my Master's Degree in KAIST (advised by Jaegul Choo). My study is based on the belief that RL in simulated environments is inevitable, let it be the data generation or building a library of atomic skillsets. In this direction, I am invested in pushing the absolute limit of RL in dexterous bimanual manipulation. There are so many exciting obstacles and tasks we can tackle; if you want to discuss anything research related, I'd be more than happy to be engaged!

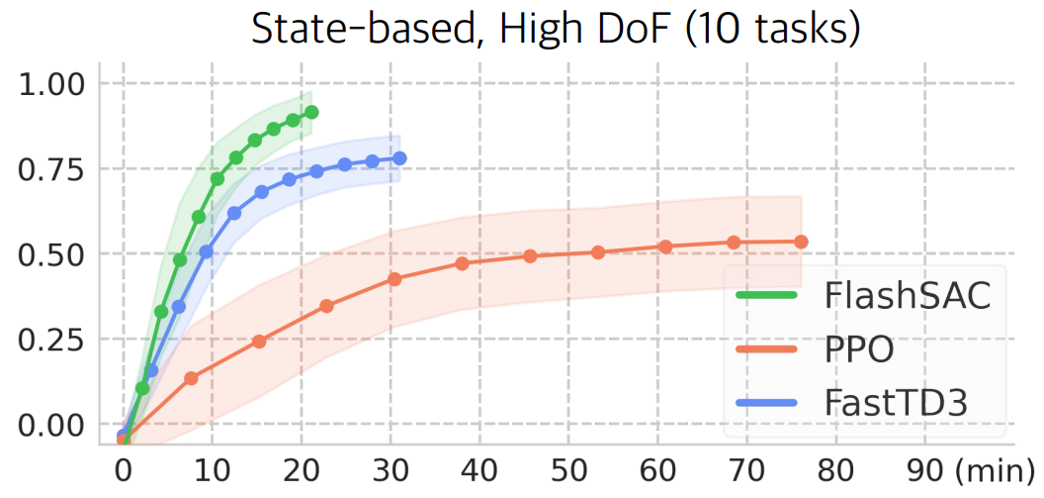
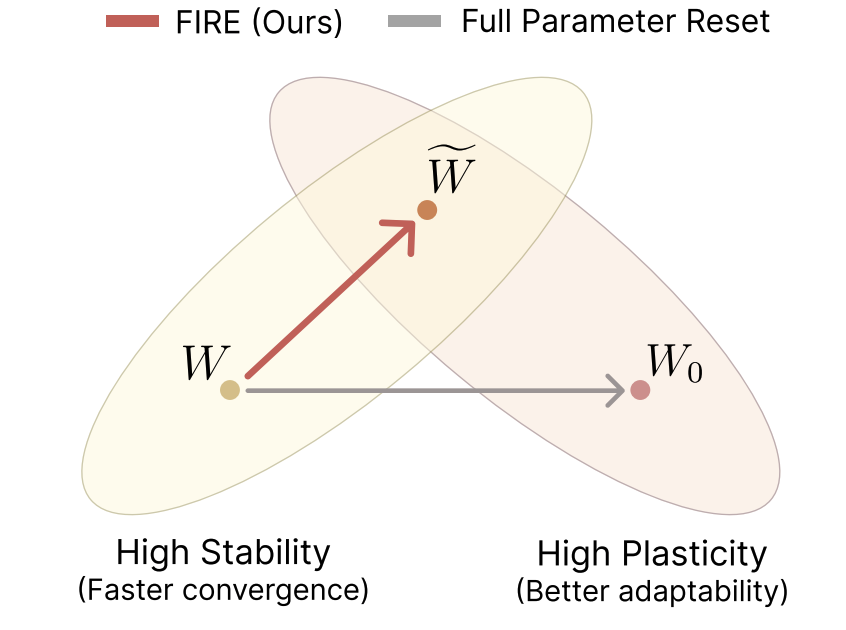
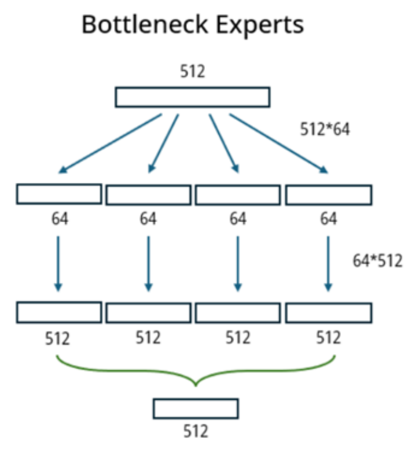
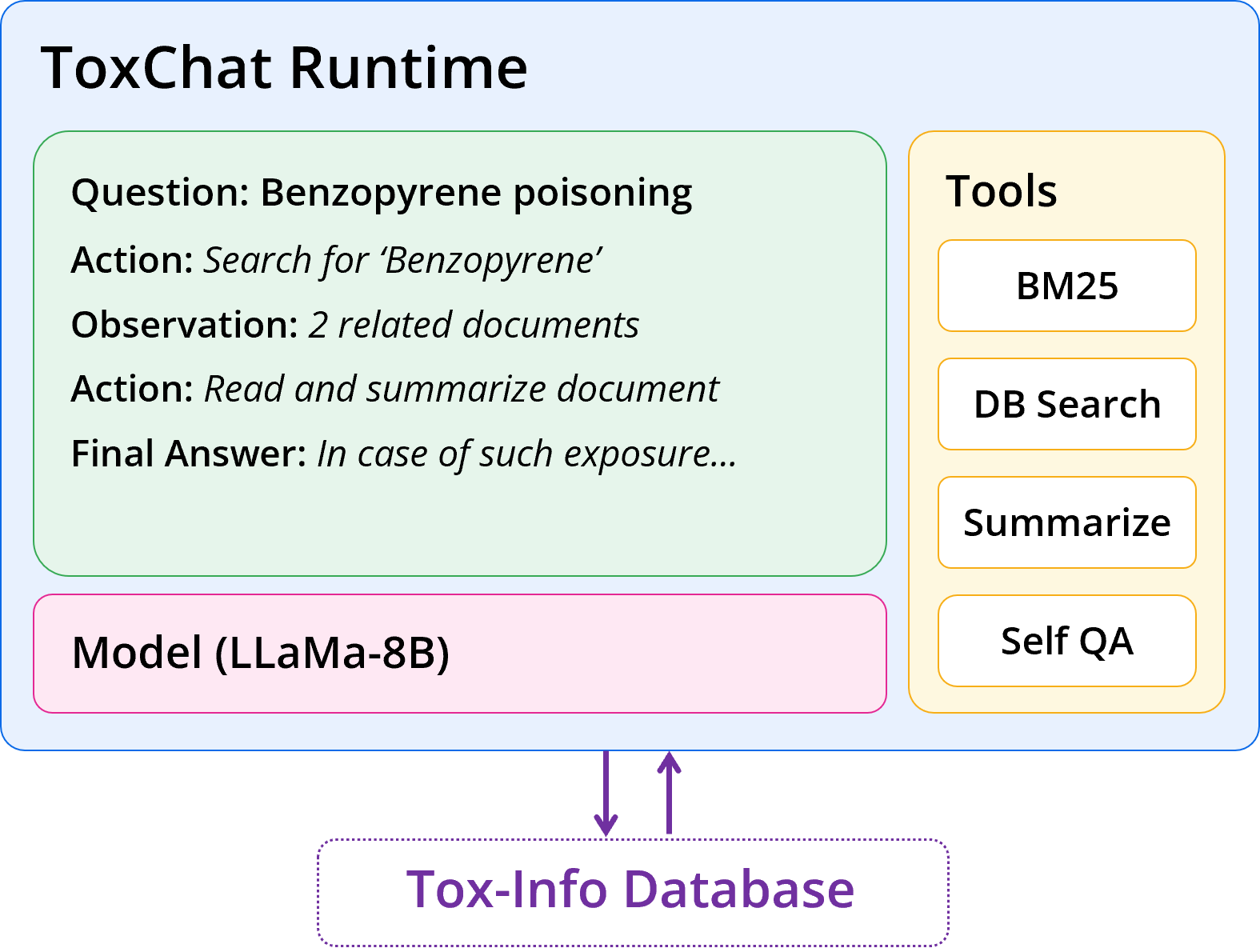
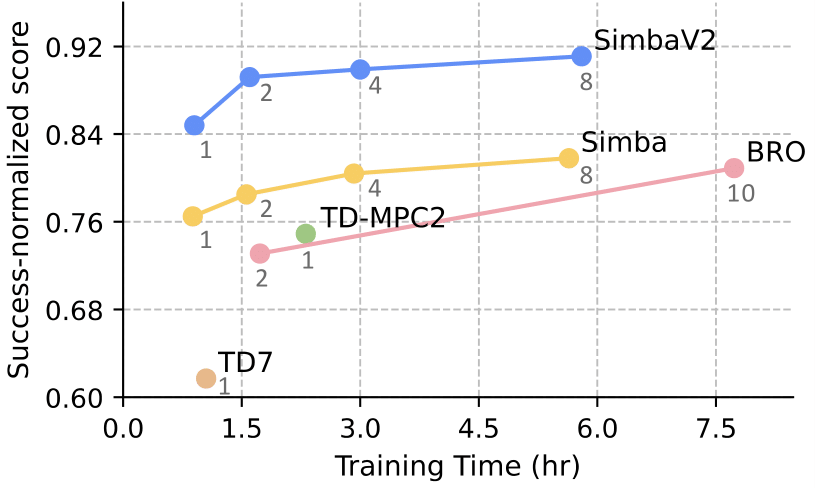
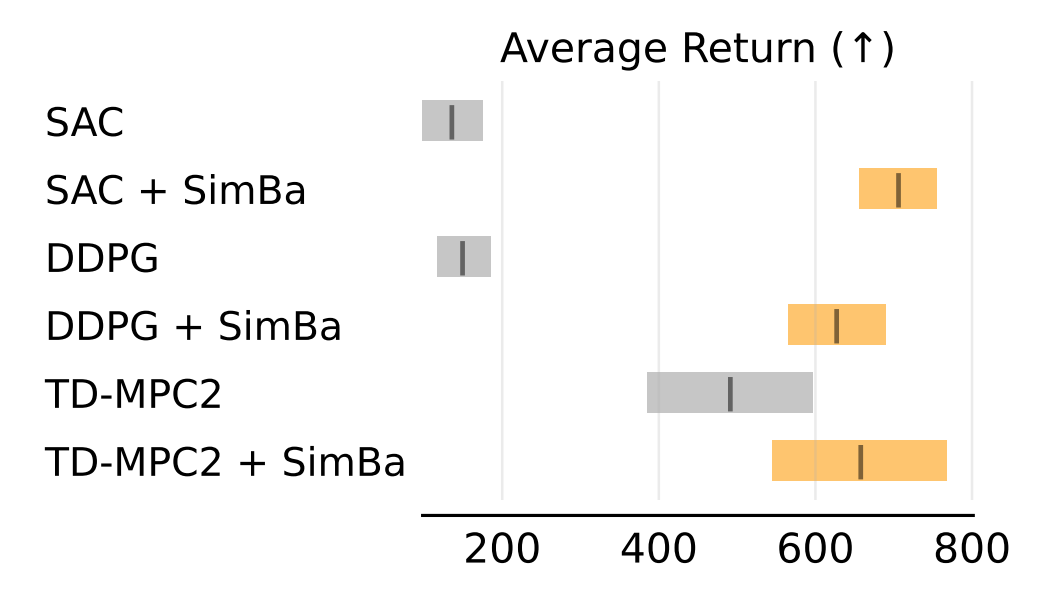
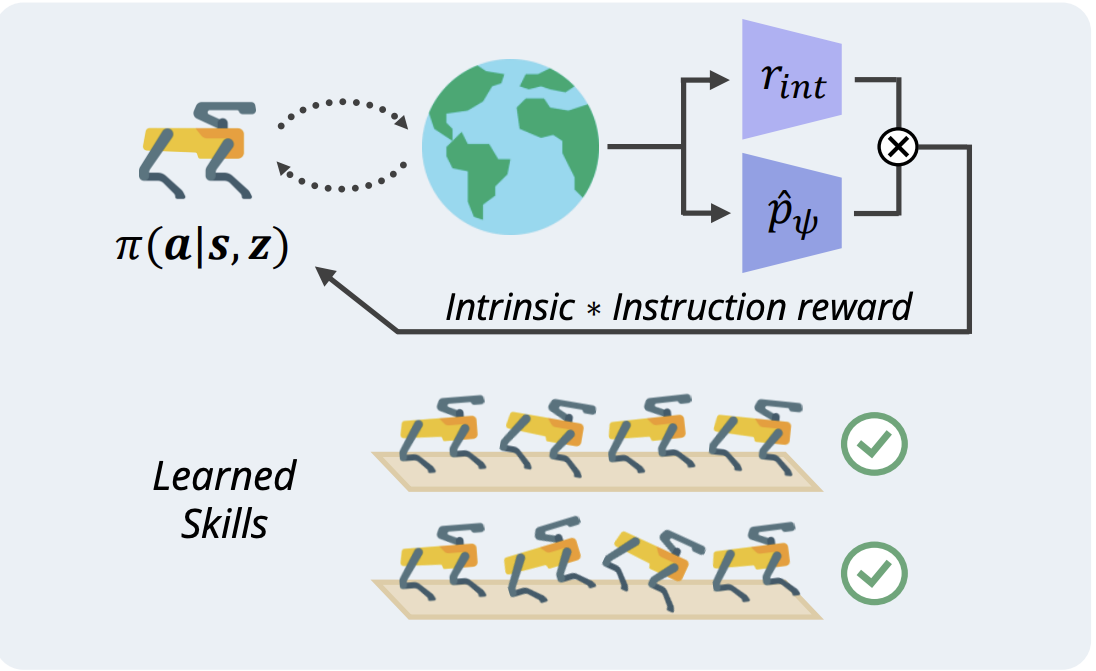
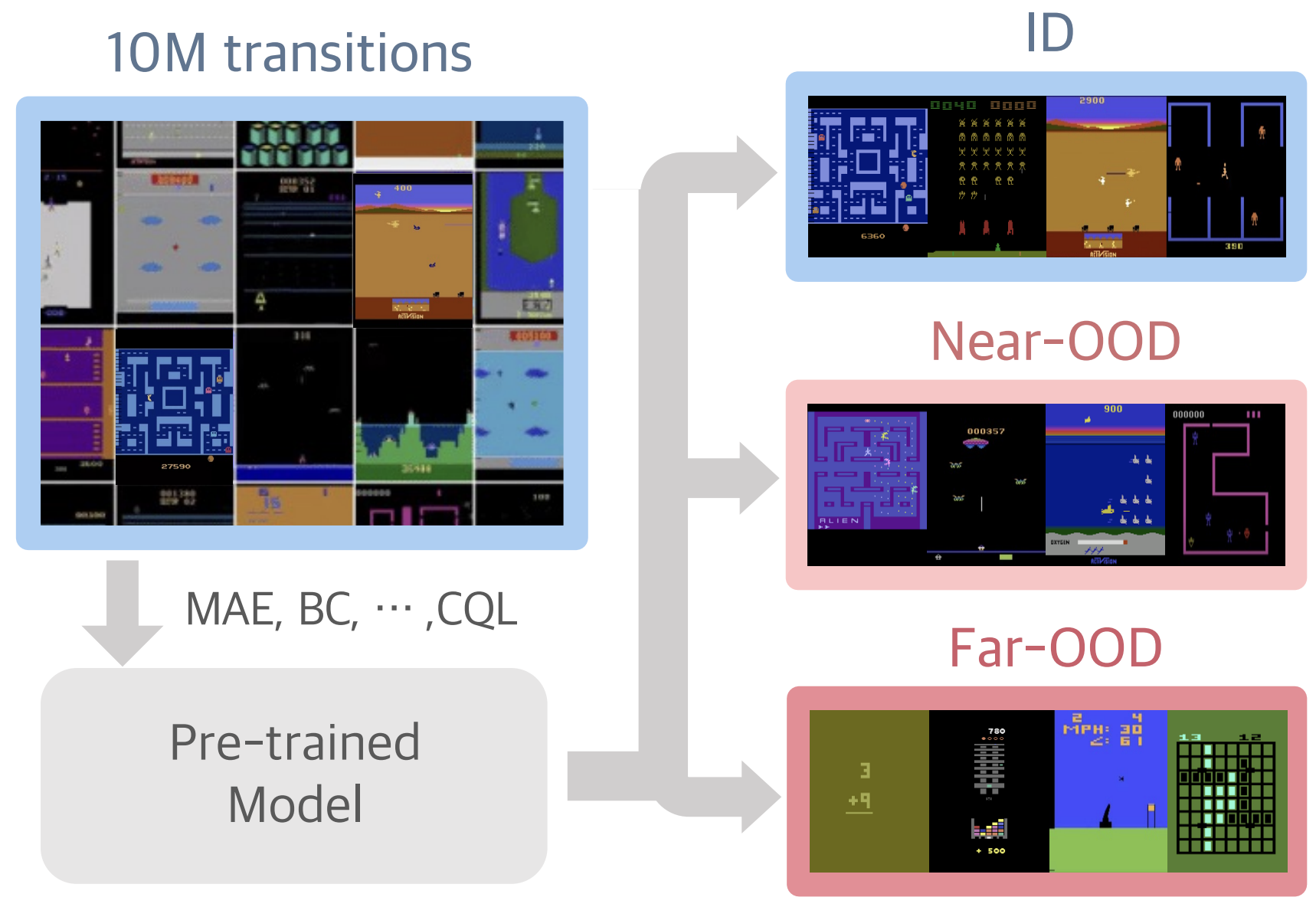


{kind=link}