![]()
![]()
Hi there, nice to meet you!
My name is Donghu Kim. I am on a Master's Degree program in KAIST (advised by Jaegul Choo), studying reinforcement learning and embodied AI.
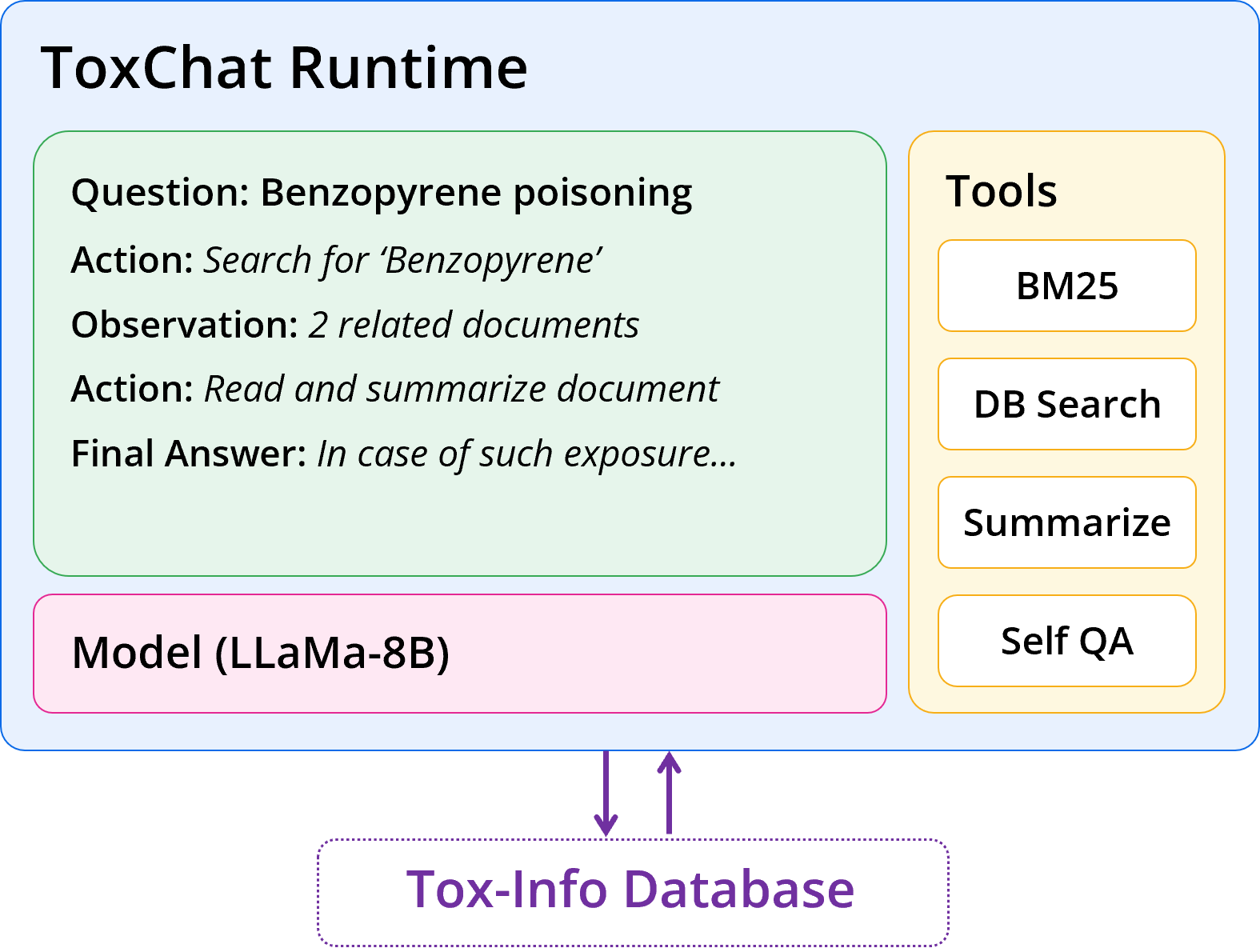
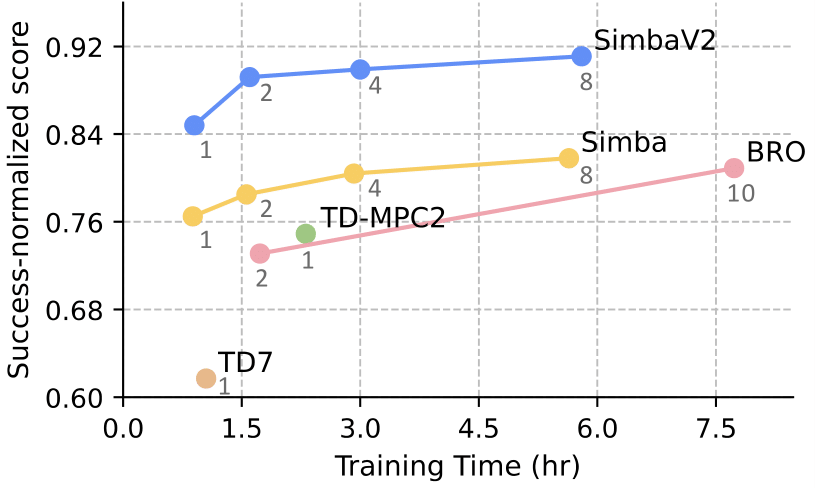
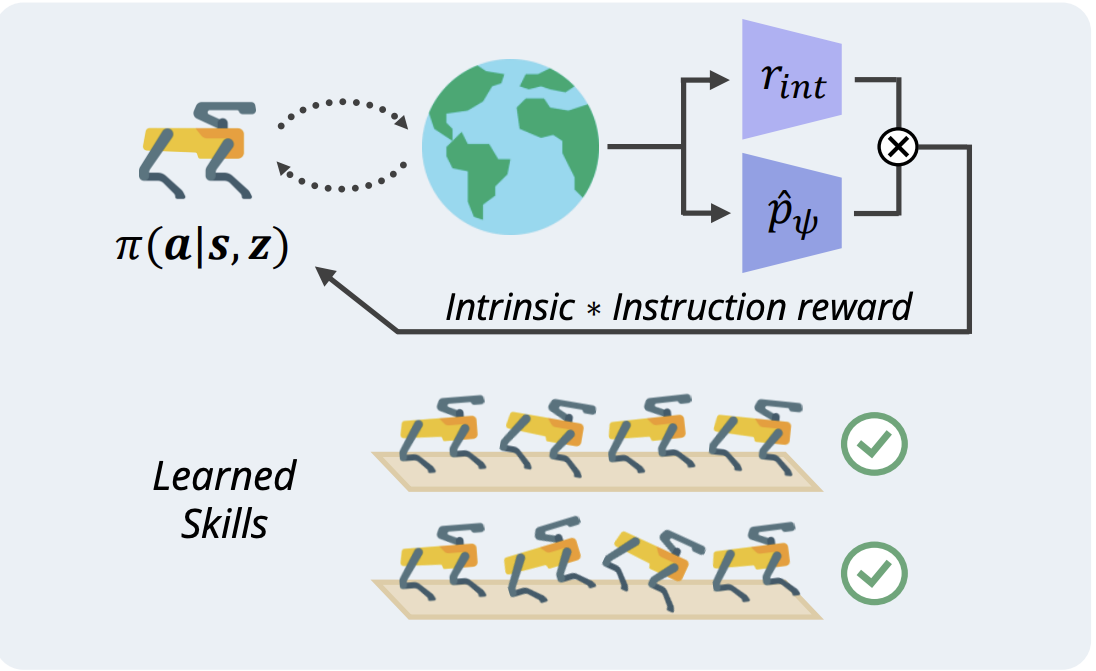
Towards building a generalist robotic agent, I am a huge believer that RL in simulated environments is inevitable, let it be low-level data generation [1, 2] or post-training of large models. In this direction, I am invested in pushing the absolute limit of efficiency in RL for control: Can we make RL work with only 1K samples? Can we do it within an hour? As far fetched as the goal may seem, there are so many exciting components we can tackle, including feature learning, exploration, architecture design, optimizer, and most interestingly, plasticity.
I still have a long long way to go; if you want to discuss anything research related, I'd be more than happy to be engaged!
Email / CV / Google Scholar / Github


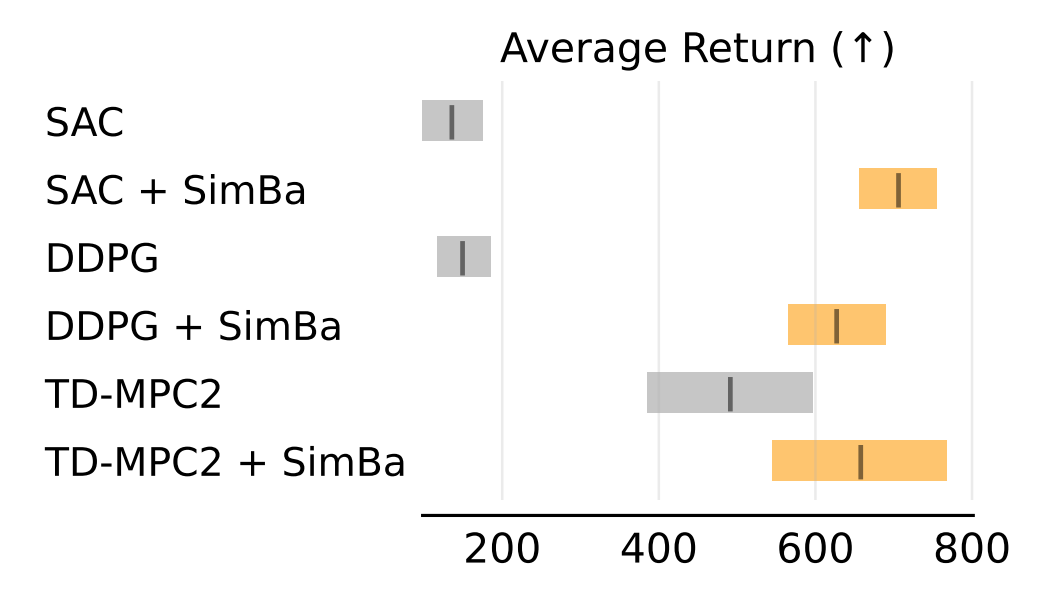
{kind=link}